其实追根溯源,微服务应该是来源于亚麻的SOA(Service Oriented Architecture),而从business的角度,应该是来源于Jeff的two pizza team的论断。如今microservice已经遍地开花,似乎一个公司没有microservice,就不能称之为现代互联网公司。但很多事情就是这样,越是所有人都熟知的概念,越容易搞不清楚。还清晰的记得去面试一个公司时被问到你们亚麻的服务发现是怎么实现的时候,竟然回答不上来。于是借着《Spring Microservices in Action》的笔记来归纳整理下。
话不多说,大概零零散散的20天时间读完,整体印象不在具体的Spring Cloud based 实现层级,而是在于整体上对microservice的几个大的方面的overview吸引了我,在retrospect当前的工作实践,发现有些方便概括的其实挺好的,下图便是读完之后一个冰箱贴上的概览。 其实这些红色comments是山人对于亚麻的一些相应基础框架做的association。因为每次读完这些业界写的书,一边试图把里面的方法和思想和公司的实践相对应,一边也发现亚麻的infrastructure做的真是比业界要走在前面。

1. 何为微服务
微服务是相对于传统大硬件下的宏服务而言的,其把一个功能复杂耦合的系统拆分成一个个松耦合的功能独立单一的子系统。书中给出了这点:
1. Application logic is broken down into small-grained components with well-defined boundaries of resposibilities.
2. Each component has a small domain and is CI independently.
3. Microservices communicates based on a few basic principles and employ lightweight communication protocols, such as HTTP and JSON.
4. The potential technical implementations of individual services is irrelevant.
5. It allows organizations to have small development teams(such as two-pizza team).
6. Spring, J2EE, Spring Boot, Spring Cloud.
a. J2EE powerful, but too heavy, and also force you to use a heavy server to deploy your services.
b. Spring Boot is a re-envisioning of Spring framework. It embrances core features of Spring, and stripes away many of the "enterprise" features found in Spring, and delivers a framework towards Java based, REST-oriented microservices.
c. Spring cloud framework makes it simple to operationalize and deploy microservices to a private or public cloud.
2. 微服务的几种Patterns
虽然微服务由business logic的需要而来,但微服务远不止business logic。微服务是伴随着大traffic,大流量而来的。越是复杂的系统,大流量的情况下,微服务的可扩展性,容错性,资源的有效利用和控制就更为有效。
2-a. Core Development Pattern
顾名思义,它是关于创建微服务本身的,涉及到比如:
[基本的微服务responsibility的定义]如何合理有效的划分微服务的粒度。一个大的service,我是应该划分为两个?三个?还是多少个微服务合适?其实这与其说是技术问题,不如说是管理的问题,一个企业如何定义高效运转的组织,如何让组织适应业务的发展而快速的变化。而反应到技术上,一个组织就是一个service。service的scope定义了组织的管理界限,责任界限,DevOps的界限。正如ashish所说的,decouple应该被视为一个高效运转的组织下,自然而言的事。业务发展了,需求变化了,decouple便成了自然而然的事情,decouple就是向microservices转变的过程。实际中,microservices的responsiblity应该以一个team为boundary。
[服务之间的通信和endpoint的定义] 一般大公司内部有一套自己的成熟的service框架,可以是基于RESTful的,也可以是基于RPC的,而这样一个service 框架往往限定了服务器之间的通信协议和方式。比如基本的XML-based的service model定义等。自己的service endpoint如何暴露给client,是否需要client独立的package定义。
[Service的配置如何管理] 比如业界常见的把code和configuration分离的观点。open source的基于某种中心化配置管理(zookeeper之类的)。亦或是企业自己的集成于一个综合的deployment框架之中(比如Apollo)
[Stream Event Processing] 如何处理异步callback,是用一个独立的listener集成,走sync的callback还是用某种Queue based的callback,比如SQS。如果走async的queue,business logic本身对于out of order的情况下tolerance有多大,如果不允许,需要从应用层来考虑如何相应的解决办法。Spring Cloud的annotation based的general的框架目前能够很好的集成业界常用的比如Kafka,RabbitMQ等stream processing framework。
[Persist选择和核心层事务状态的管理] 是基于RDMS还是NoSQL的persist,如何处理基本的DB的脏读和幻读的问题。如何scale up DB,提高DB的读写,已经高并发情况下DB的persist瓶颈。如何track和维护 service里的核心business logic以正确的预期的方式来展开?如何处理异常情况,是否需要某种workflow enginee来drive整个过程的完成。对于需要retry的logic,best practises是啥?突然想到一个问题,DB persist为什么没有retry,对于microservice而言,纯粹的db transaction management能难对跨service的statement做管理,相应的rollback策略也是不可行的。
2-b. Routing pattern
这里其实就是指服务发现。服务发现其实远比想象中的重要。比如在流量高峰期,进行快速的水平scale up,从而以一种可持续的方式进行。或者如果发现一个service下的某个instance机器有错误,便可以快速的从服务发现中移除。或者在每台机器部署时,自动通过默认的health check的接口,来实现自动的问题实例移除。从实现的角度,最为传统的方式是通过直接DNS的load balance来实现。当然这种传统的DNS都是基于传统软件开发的大机器硬件条件下的软硬件结合体。水平扩展能力很低,最常见的是只有一个主备,且备不是用来走水平扩展,而是为了在主完全失效情况下的切换迁移。更别用说如今cloud-based的services实现。对于短期内高流量情况下的处理能力很差。用书上的概括,缺点主要有:
i. Single point of failure.
ii. Limited horizontal scalability.
iii. Statically managed.
iv. Complex.
而现代的服务发现方式一言以蔽之,就是用microservices本身来替代传统的DNS负载均衡。把传统IBM式的大机器硬件下的macro service变成去IOE化的高扩展容错的micro service。其用如下方式来解决service discovery的基本responsibility。
- Service registration. 相比传统DNS,registration本身就是一个microservice,其由多个nodes组成。当一个service instance启动,它边把自己register到service discovery上。
- Client lookup of Service address. client上不是一个service的物理地址,而是service discovery的地址,path上可以包含要访问的service的logical名字。
- Information sharing between discovery nodes. 由于service discovery本身是distributed的microservice,它可以维护一个中心化的DB或者是zookeeper之类的配置管理。当一个client访问到任何一个service discovery的节点,其信息是同步共享的。
- Health monitoring of discover service and the service instance. service discovery可以实现任意的service health的探测脚本,shadow的或者是deep的,甚至是自定义的都可以,而不是局限于负载匀衡自己的实现。service层级的registration也可以自己配置,比如每次service activate时,它需要向service discovery重新注册自己。
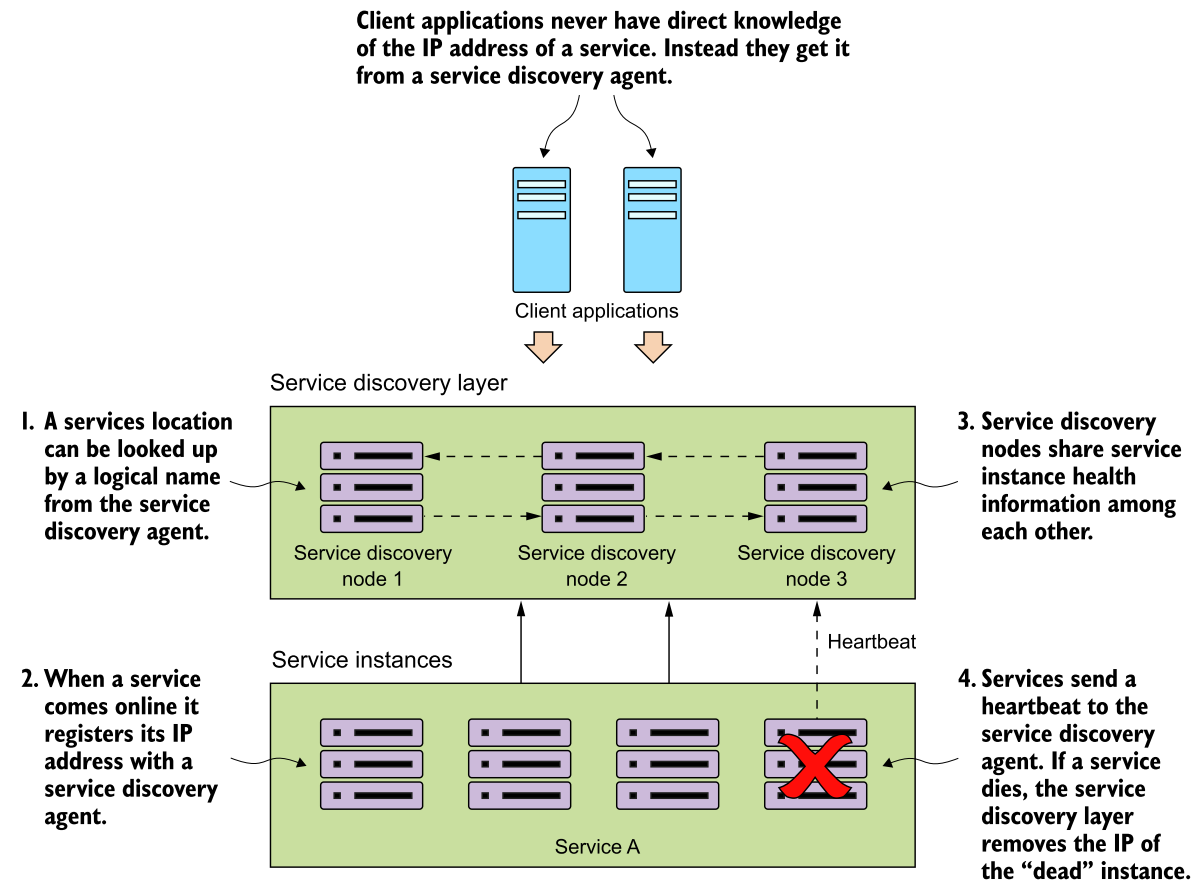
当然其实service discovery不是独立存在的,其和2-f中的deployment框架应该是依赖的。从service的code本身应该有一些deployment相关的配置和逻辑,然后deployment的framework把这部分抽象,来跟service discovery交互,做到对开发人员真正的透明。
2-c. Client Resiliency Pattern
Resiliency 即the capacity to recover quickly from difficulties; 随着operation时间的越来越长,包括peak day的war room的次数的增加,山人的切身体会是,高流量从来不是大问题,通常projection的都算准确,即使不准确,在有人值班时,提前的auto scaling都是可以做到smooth进行的。而真正的问题来自几个地方:
- 某个上下游的dependency service挂了,或者是某个service出现了throttling,当前service没有很好的resource隔离,或者是一定粒度下的throttle,最终导致当前service的resource全部被问题的dependency所占据,最终引发整个系统挂掉。
- service本身在外部流量正常情况下,出现了各种CPU或者memory报警。通常这种情况是由于某种service内部的某种while(true)类似的bug,导致资源无尽的消耗,而且这时候,所以在1条件下能做的措施都无效了。唯一能做的只能一边不断的重启,热替换。一边尽快找出问题的原因,如果问题是由于某个近期引入的bug,那么rollback是理想的选择,如果问题是由于某个外部不正常的输入,此时应该找到问题的transaction,来进行隔离,不管是从workflow层级,还是从DB层级,都需要。如果是workflow,需要评估是否需要把问题的workflow置成暂时error status,停止其占用resource。 但其实往往CPU的问题,从系统的ps方面能难debug,往往需要实时的查看profiler或者实时的看GC情况等。还记得5年前vbs的sev1么?
- 整个网络层面或者是基础service层级的问题。这种一个典型的现象,各个region,上下游service几乎全部出现了报警。mitigate的方式也是具体问题具体分析,但通常能做的不多,发生的概率也很少。
相比之下,之前很长一段时间,很多工程师对这种resiliency有种忽视的感觉,而在以更多的是那种完全的失败,比如各种层级的冗余,备份策略等等。个人感觉,这种情况很少见,往往局部的问题,比如service性能出现问题,不间断的出现某种fatal等。而相应的处理策略包括:
[Client-side Load Balancing]. 即service client来cache service的endpoint,因而不必每次都从service discovery去拿, 只有等client发现该endpoint无效时才重新去retrieve。这样能够有效降低service discovery的压力和瓶颈。问题就是针对discovery service实现的某些load balancing的策略显得无效,
[Circuit Breakers]. 即如果发现client call某个service一直有某种异常, 或者频率太高,就执行短路操作。这样有效的避免了1情况可能出现的绕过service端负载均衡的问题。
[Fallbacks]. 即如果当前service挂了,是否有替代的方案。比如某种standin services。
[Bulkheads] 即资源隔离。就像使用不同的线程池对不同的服务进行隔离,从而有效方式某个特定的服务或者功能的挂掉,影响所有的服务。用书中的概括:
In a microservice application, you'll need to call multiple microservices to complete a particular task. Without using bulkhead pattern, the default behavior is that the calls are executed using the same threads that are reserved for handling requests for the entire java container. In high volumes, performance problem with one service out of many can result in all of the threads for the java container being maxed out.
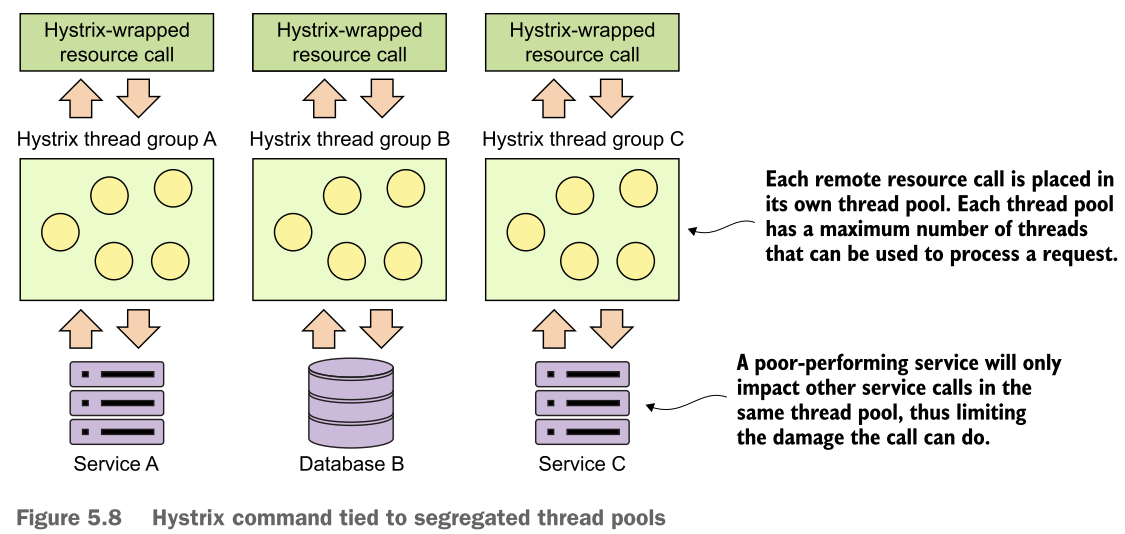
个人觉得资源隔离是非常有效,而且几乎是大块头大流量service必须要考虑到的方法。
2-d. Security Pattern
如今的时代,security几乎可以肯定是任何企业不改怠慢的点。它直接让facebook这种蒸蒸日上的公司变得半死不活。如今好像service之间的认证基本都是通过OAuth2这种方式来实现。但特别觉得受用的一点是书中关于认证和授权的区别的介绍。
On Authentication vs. Authorization. Authentication is the act of a user proving who they are by providing credentials. AUthorization determines whether a user is allowed to do what they're trying to do. E.g. the user Jim cloud prove this identity by providing a user ID and password, but he may not be authorized to look at sensitive data, such as payroll data.
其实除了上面的两个A,应该还有一个Accounting。
2-e. Logging and Tracing Pattern
正如微服务的优点是把复杂的monolithic系统变成一个个独立,简单,可有效管理的子系统。其带来的一个问题是针对一个transaction的trace变得很难。尤其是不同service之间的trace和debug会花费很大的时间。基本的方法包括:
- A Correlation ID for tracing.
- Log aggregation.
- Visually trace a transaction
2-f. Build and Deployment Pattern
开发和部署这块的内容很多,而且往往是反映企业基础架构能力的很重要一环。书中基本的思想来源于DevOps下的CI。
So long, and thanks for all the fish.