Transformer Learning Notes
Transform的架构基本已经占据了NLP的大部分SOTA models,尤其是一些大模型,比如BERT,GPT。在CV领域也有了Vision Transformer的应用。在multi-modality的应用还是比较广泛的。最近team里面做了一个Transform based架构的knowledge share,再结合李宏毅老师的一些slides,记录一下有些对于自己来说比较cores的知识点。
经典Transformer架构如下所示
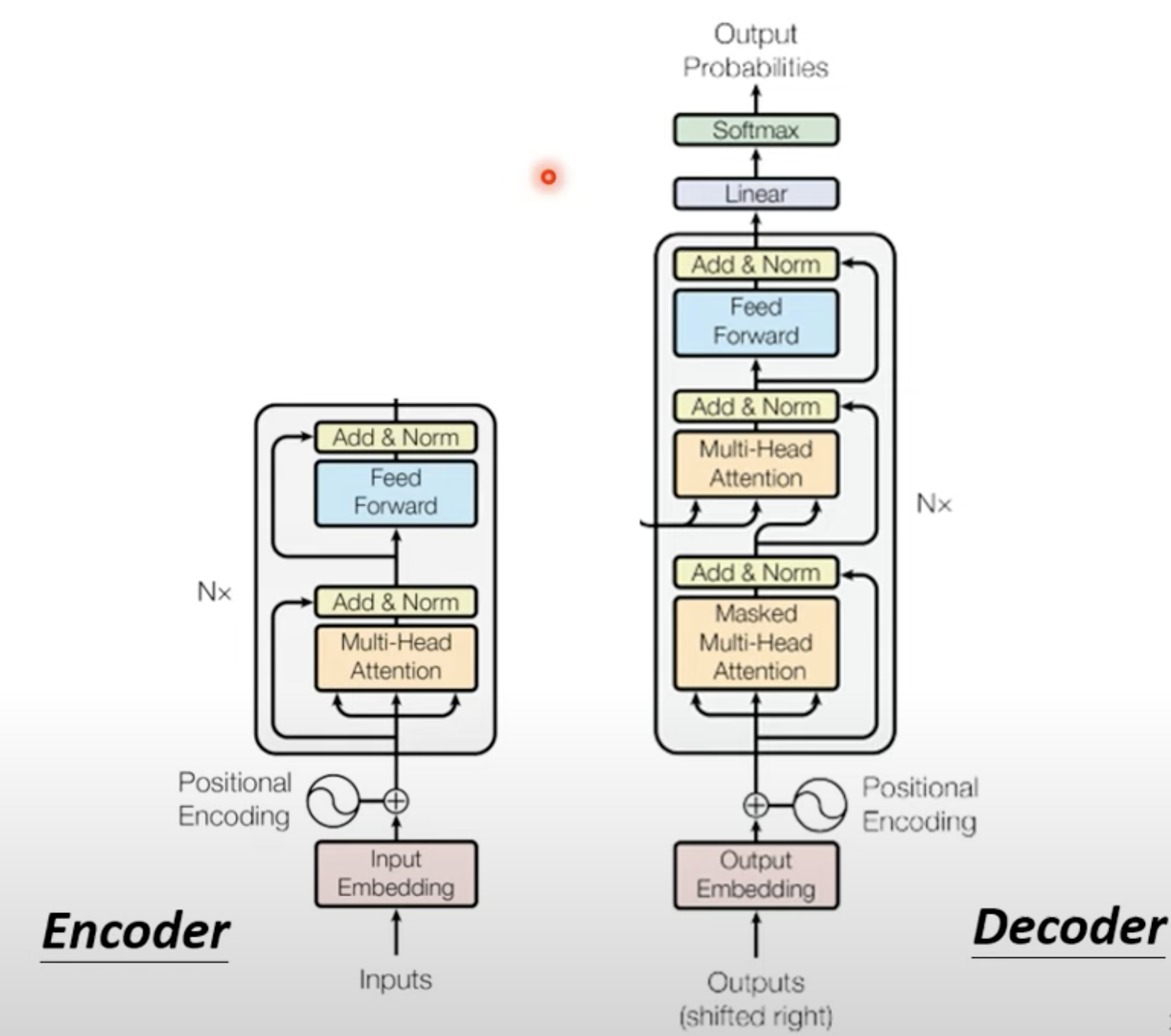
1. Encoder
Encoder的输入和输出向量长度是一样的。而Decoder的输出长度是不确定的。由model自己决定。
2. Decoder in Transformer
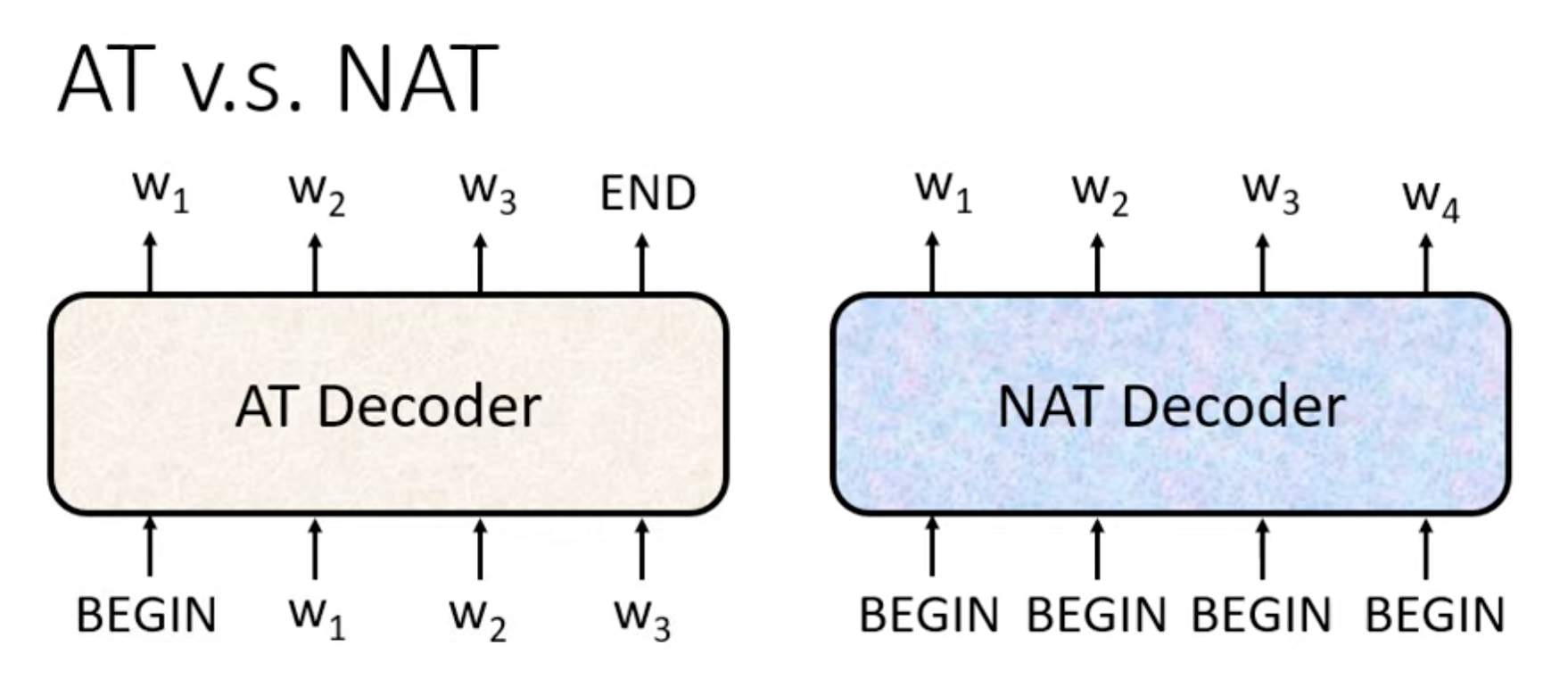
- AuToRegressive Model (AT)
- Non AuTo Regressive Model(NAT)
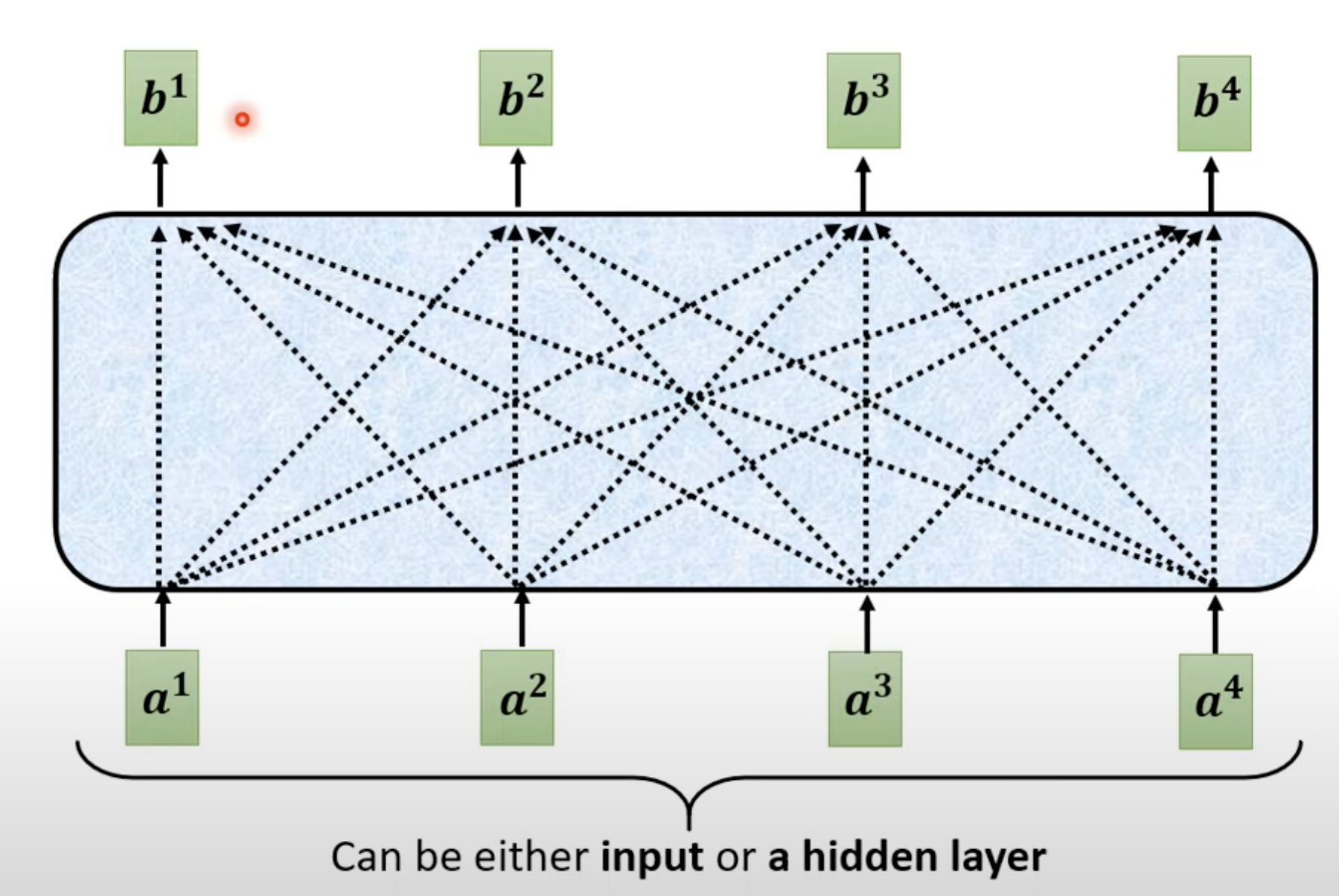
2.2 Self Attention → Masked Self-Attention
Self Attention 指的是每次attention的output都需要参照所有的input。比如b1的output是要参照a1,a2,a3,a4的。
而masked self attention指的是产生b1的时候指看它之前和当前a1的input。而到b2时,只考虑a1和a2的结果。
2.3 Cross Attention v.s. Self Attention
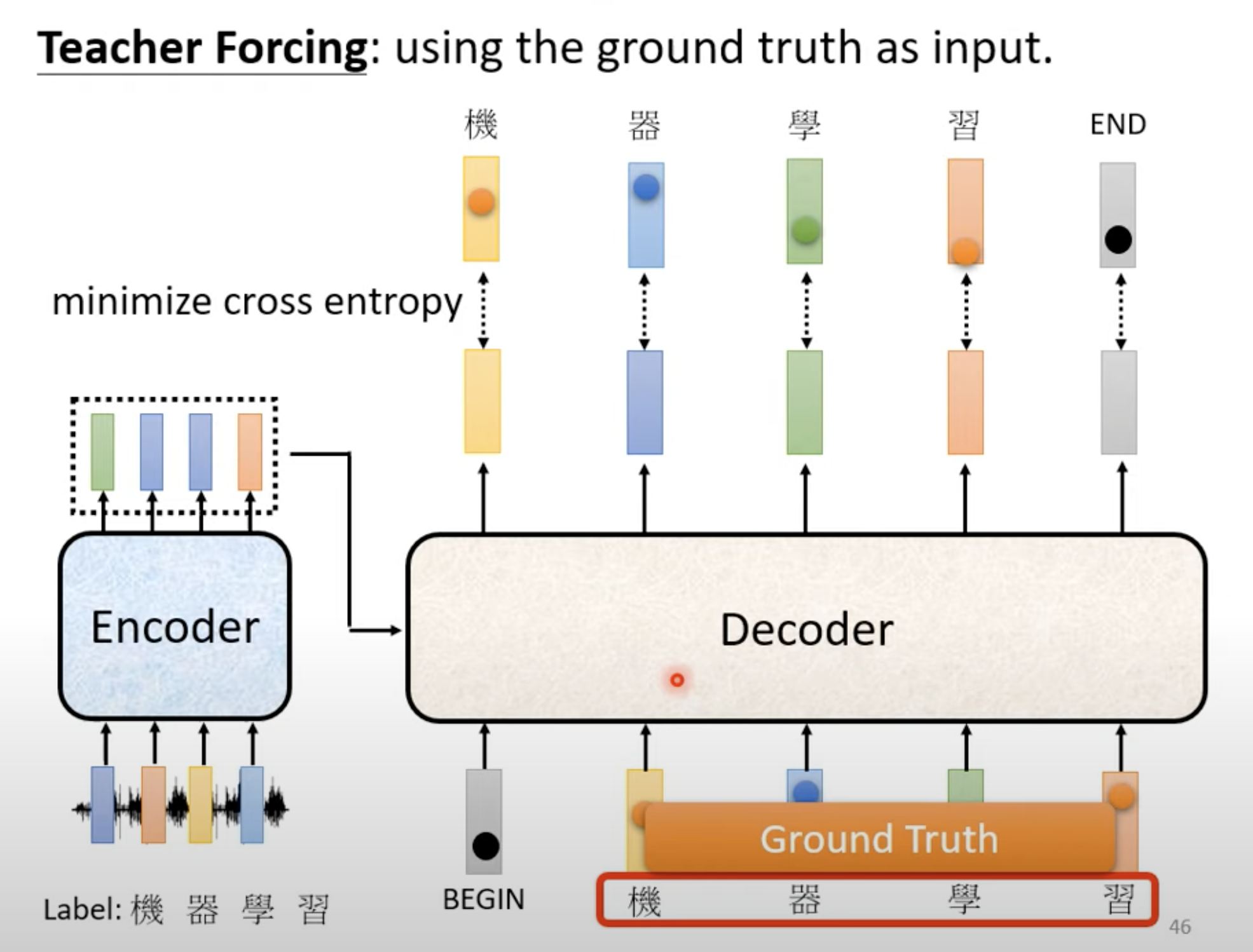
3. Training
- Cross Entropy to compare the output and ground truth.
- Decoder’s input is the ground truth.
Tips
- Copy Mechanism.
- Guided Attention.
- Optimization Evaluation Metrics
- Training → Cross Entropy
- Testing → BLEU score.
- Exposure Bias
- Decoder在训练时都是正确的,但是在测试的时候可能是错误的。因此,可以考虑在训练的时候给Decoder一些错误的东西,即Scheduled Sampling.
- Original Scheduled Sampling.
- Scheduled Sampling for Transformer.
- Parallel Scheduled Sampling.
- Decoder在训练时都是正确的,但是在测试的时候可能是错误的。因此,可以考虑在训练的时候给Decoder一些错误的东西,即Scheduled Sampling.
So long, and thanks for all the fish.
参考
[1] 李宏毅Transformer课程.